
Datenmigration leicht gemacht mit SQL Workbench/J
Habt Ihr schon einmal vor der Herausforderung gestanden, Daten von einer Datenbank in eine andere zu migrieren, vielleicht sogar zwischen unterschiedlichen DB-Anbietern? Egal ob Ihr von einer on-premise Netweaver Portal Lösung zur SAP BTP, von einer HANA DB zu PostgreSQL auf der SAP BTP zur Kostenersparnis wechselt, einen Anbieterwechsel der Datenbank vornimmt oder auf ein neues Datenbankmanagementsystem umzieht – Datenmigration ist oft unerlässlich, kann aber auch sehr komplex sein.

Warum SQL Workbench/J?
Die kostenlose Tool Unterstützung durch SQL Workbench/J kann eine Lösung für solche Herausforderungen bieten. Im Rahmen unserer InnovateSAP Initiative setzen wir auf SQL Workbench/J, um Migrationsherausforderungen zu lösen.
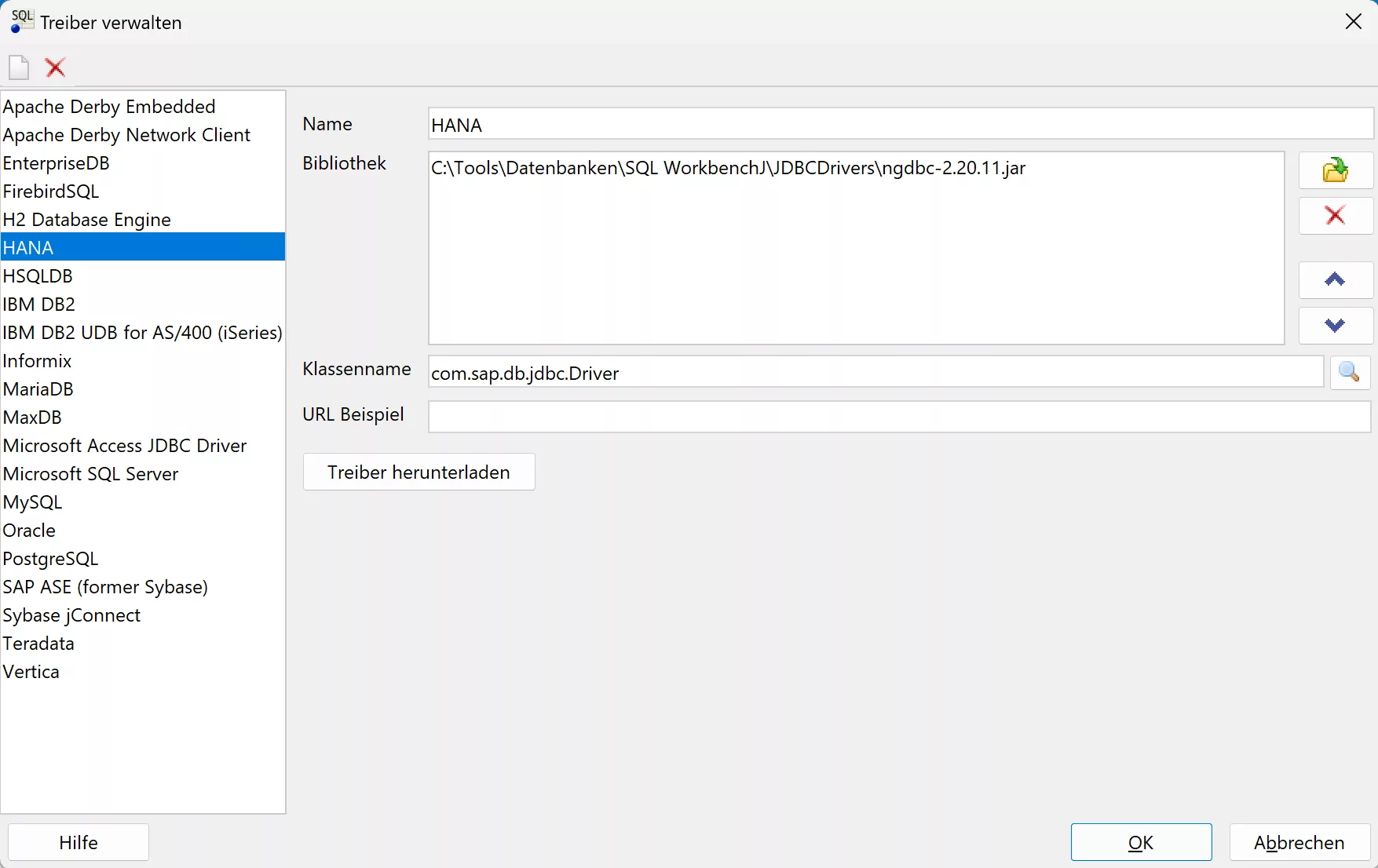
Die benötigte Verbindung zu Quell- und Zieldatenbanken und auch die Pflege von vordefinierten und zusätzlichen JDBC Treibern (z.B. für HANA) gestaltet sich relativ unkompliziert. Hier wurde ein HANA JDBC Treiber angelegt:
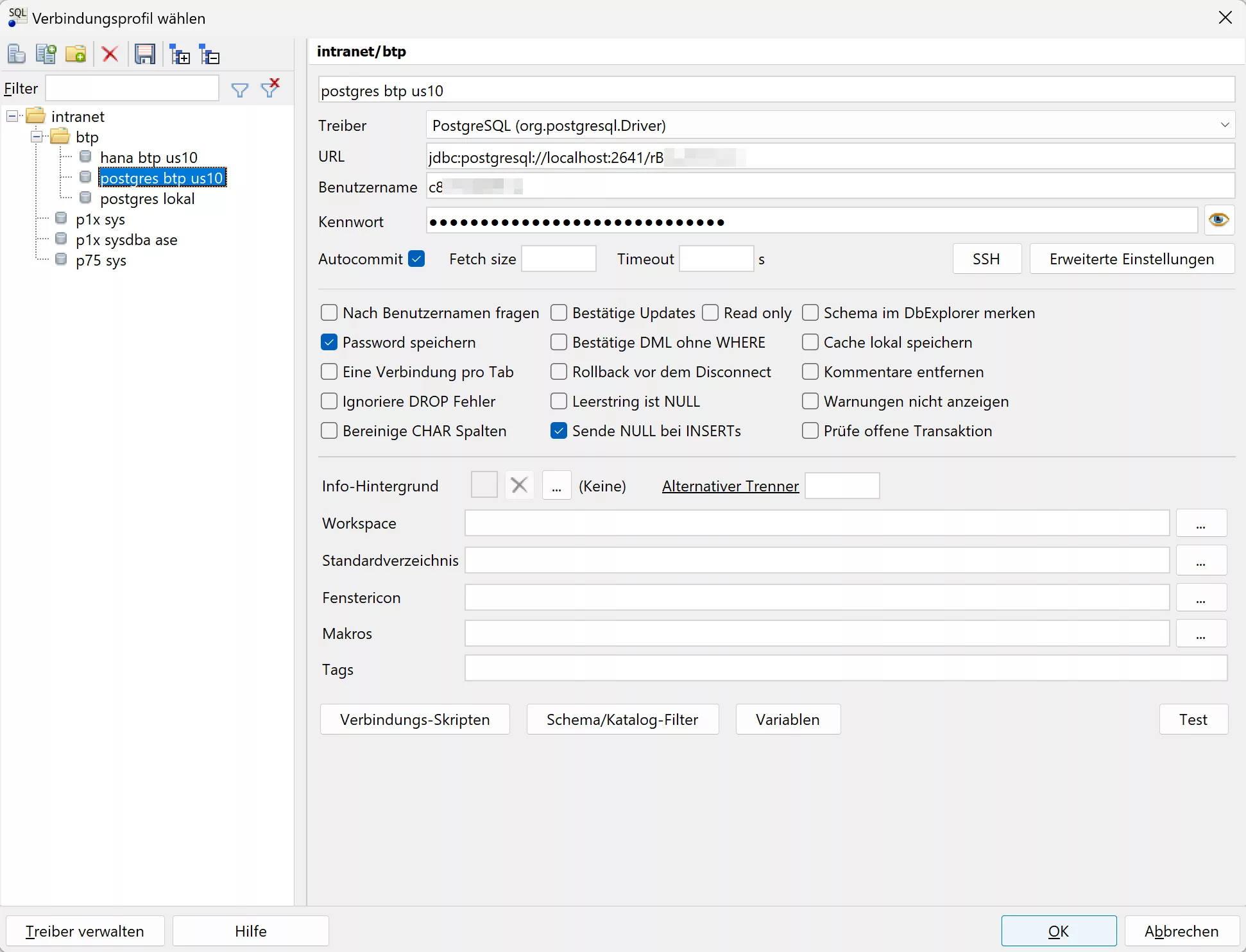
Hier wurde eine PostgreSQL Verbindung gepflegt (die einen SSH Tunnel zur SAP BTP benutzt):
SQL Workbench/J unterstützt eine Vielzahl von Datenbanken, darunter (mal mehr mal weniger offiziell): Oracle, MySQL, PostgreSQL, SQL Server, DB2, Sybase, MS Access, Firebird, Apache Derby, HSQLDB, Informix, InterSystems Caché, MariaDB, Netezza, Pervasive PSQL, SQLite, Teradata, Amazon Redshift, Vertica, Greenplum, SAP MaxDB, Snowflake, Amazon Athena, Apache Hive, Google BigQuery, Presto, SAP HANA. Diese breite Unterstützung ermöglicht es, praktisch jedes Datenmigrationsvorhaben im SQL Bereich zu bewältigen.
Übliche Migrationshürden
Eine der häufigen Herausforderungen sind beispielsweise Blob Felder (Binärdaten von nahezu unbeschränkter Größe), die sich zum Beispiel mit dem Oracle SQL Developer von Oracle nicht als CSV, Excel oder JSON exportieren lassen. Diese Dateien könnten durch Binärdaten extrem groß werden.
Ein ohnehin sehr arbeitsintensiver manueller Export und Import von Dateien ist in diesen Fällen also nicht nur, fehleranfällig, aufwendig und schlecht reproduzierbar – Er ist schlicht unmöglich.
Anlegen von Datenstrukturen
Das Anlegen der Tabellen, Indizes und gegebenenfalls Funktionen kann je nach Anwendungsfall entweder per SQL direkt oder durch eure Entwicklungstools erfolgen. Eine besondere Hilfe kann hierbei die künstliche Intelligenz sein, beispielsweise beim Erstellen des neuen Datenmodells basierend auf der alten Datenstruktur oder beim Anpassen der Create-SQL-Skripte an einen neuen Hersteller oder Namensraum. Bereits ChatGPT 3.5 ist hier eine gute Hilfe.
Umsetzungsprozess
Mit dem Data Pumper von SQL Workbench/J könnt Ihr die Datenmigration effizient durchführen. Nachdem die Verbindungen zur Quell- und Zieldatenbank hergestellt wurden, kann die Migration mit einem umfassenden Set an Optionen gesteuert werden:
- Auswählen der Datenquelle (Tabelle oder SQL Select) und des Ziels – Hier mit SQL Quelle anstatt einer Tabelle:
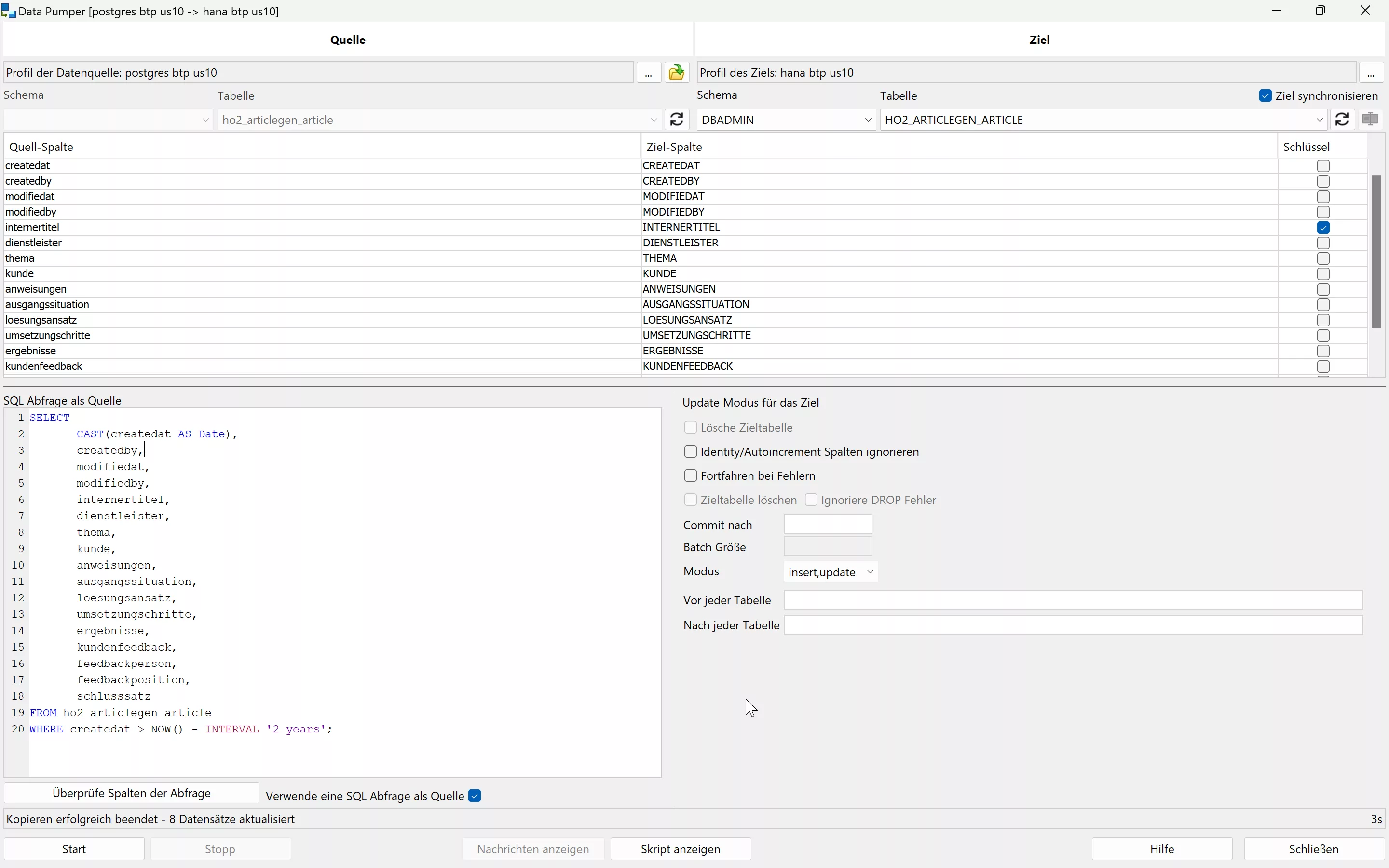
- Manuelle Zuordnung der Tabellenspalten, falls nötig
- Festlegen des Modus zum steuern von Update/Ersetzen vorhandener Werte im Ziel
- Einstellen der Batch-Größe für optimierte Performance
Ein Kernaspekt in diesem Prozess ist die Wahl des Modus, um festzulegen, wie oder ob vorhandene Werte ersetzt werden sollen. Eine falsche Auswahl führt zur Laufzeit zu Fehlern. Mögliche Modi sind:
- Insert
- Update
- Insert+Update
- Update+Insert
- Upsert
Aus Performancegründen und um Fehler zu vermeiden, ist es ratsam, den Modus zu wählen, der häufiger erfolgreiche Operationen ermöglicht, also Insert bei nicht existierenden Schlüsseln oder Upsert, um vorhandene Werte zu aktualisieren oder neue Datensätze hinzuzufügen. Um eine optimale Leistung zu gewährleisten, empfiehlt es sich, Datensätze in Batches einzufügen oder zu aktualisieren, typischerweise in Größen von 100 Datensätzen pro Batch, um übermäßige Commits zu vermeiden.
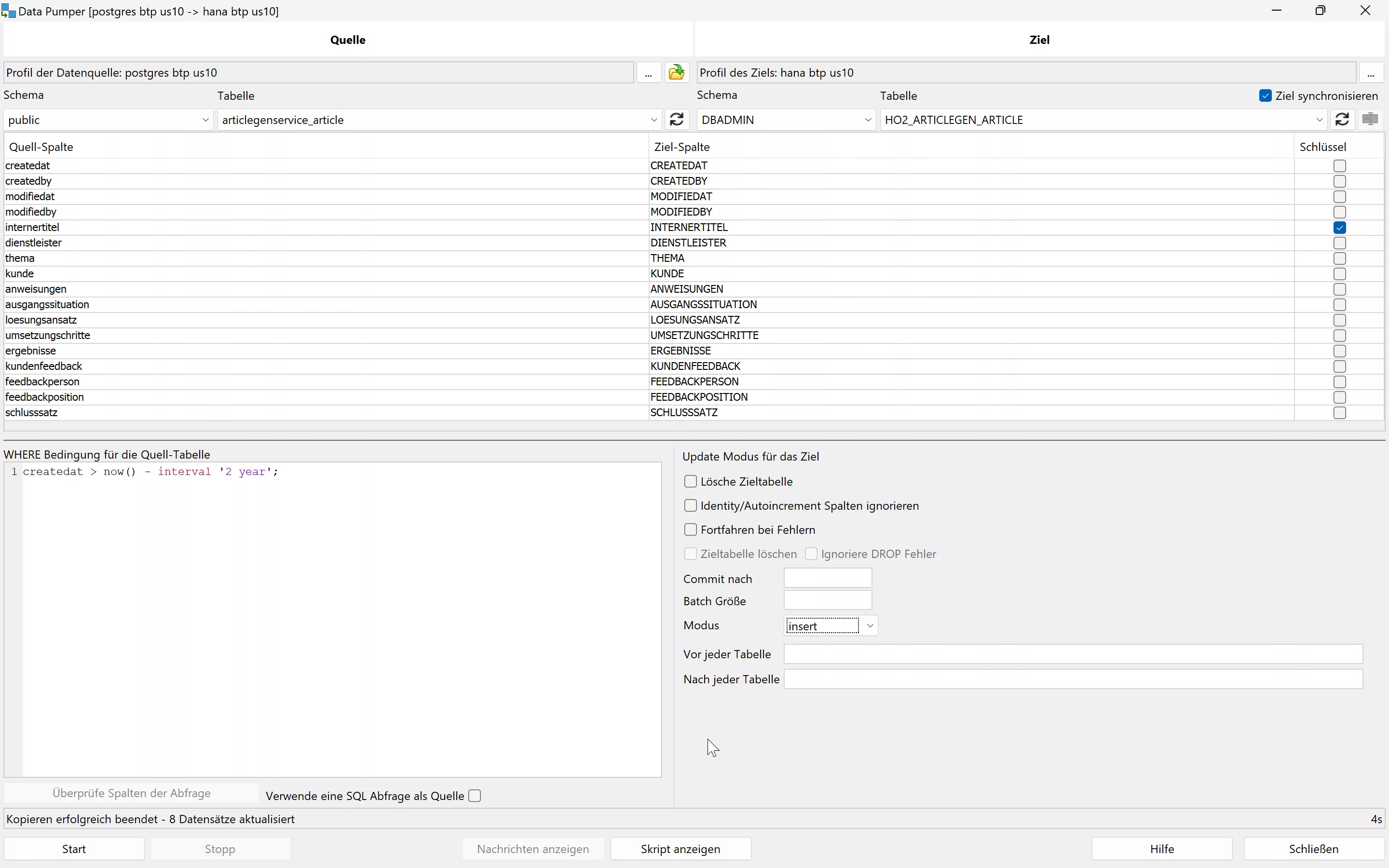
Mit der Unterstützung von SQL Workbench/J können Daten effektiv und schnell migriert werden.
Exportierbares Skript
Für die planmäßige Durchführung einer Datenmigration ermöglicht SQL Workbench/J den Export der Data Pumper Funktion als Skript. So erzeugt man schrittweise ein ausführbares Skript mit einem WB Copy Befehl pro Tabelle. Die Migration wird dann auf Knopfdruck durchführt. Falls nötig können in dem Skript natürlich auch normale SQL Befehle vorkommen.
Hier ein Beispiel bei dem eine Tabelle mittels einer SQL Query von Oracle auf SAP ASE (früher Sybase SQL Server) migriert wird und Default Werte gesetzt werden.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | WbCopy -sourceProfile='p75 sys' -sourceGroup=intranet -targetProfile='p1x sysdba ase' -targetGroup=intranet -targetTable=SAPSR3DB.TCM_EMPLOYEE_DATE -sourceQuery="SELECT ID, CONTACT_INTERN, IS_BACKOFFICE, NVL(HIRE_DATE, TO_DATE('2099-01-01','YYYY-MM-DD')) as HIRE_DATE, NVL(FIRE_DATE, TO_DATE('2099-01-01','YYYY-MM-DD')) as FIRE_DATE, VACATION_DAYS FROM SAPSR3DB.TCM_EMPLOYEE_DATE " -ignoreIdentityColumns=false -deleteTarget=true -continueOnError=false -batchSize=100 ; |
Ein solches Skript macht eine Datenmigration zwischen unterschiedlichen Datenbankanbietern einfach und unkompliziert realisierbar.

Kontakt
Wir stehen Euch gerne für weitere Fragen zum Thema Datenmigration und zur InnovateSAP Initiative zur Verfügung. Bei Herausforderungen oder spezifischen Anfragen, zögert nicht, uns anzusprechen. Gemeinsam finden wir eine Lösung!



